Week 2 of Structuring Machine Learning Projects
The objectives for this week are:
- Understand what multi-task learning and transfer learning are
- Recognize bias, variance and data-mismatch by looking at the performances of your algorithm on train/dev/test sets
Error Analysis
Carrying out error analysis
Video #1 talks about error analysis where you look at problems where your dev set misclassifies, e.g. if you’re getting 10% error (90% accuracy) which might still lead to a “ceiling” of performance.
Pick ~100 misclassified samples (just to get a sense of the problem), and figure out which categories contribute most to misclassification (e.g. cats are misclassified more as great cats than being misclassified as cat-looking dogs) and focus on that category for the greatest bang for buck.
Cleaning up incorrectly labelled data
Video #2 talks about what to do if you have mislabelled samples.
In your training set, you could just leave it as-is if the errors aren’t too many, and a bit random. Deep learning algorithms are quite robust against random errors, but not systematic errors, i.e. all yellow cats are mislabelled as golden retrievers.
For dev/test set, you can add another category to your error analysis called “mislabelled”, and again: only fix mislabelling if it contributes significantly to the misclassification.
Build your first system quickly, then iterate
Video #3 talks about error analysis before starting out on a new project. Build the first version quickly, then iterate.
- set dev/test set and metric (set the target)
- build initial system quickly (hit the target)
- next steps prioritised from bias/variance analysis, error analysis
Mismatched training and dev/test set
Training and testing on different distributions
Video #4 says deep learning works well on a lot of data, and teams tend to chuck all data they can find into a project. There are some subtleties.
E.g. lots (200K) of data from webpages (professionally shot and framed), and less (10K) data from mobile photography look different (latter is low-res and blurry). If you app focuses on mobile market, you might just want to pay attention to the latter set. But the latter set is smaller.
Things you shouldn’t do is combine, randomly shuffle (same distribution) and split. The dev/test will still have a low number of mobile photos.
Instead, do: dev/test set all be mobile images, and the training set could be anything else, with some mobile images.
The big question is, how many of the mobile images should go into train, and how many into dev/test?
The recommendation is something like 2K of the mobile-only images into dev/test (because this is the “real” data you care about in your app) and 8K mixed in with pro photos in training so that the training set contains enough REAL data to avoid having a data-mismatch problem.
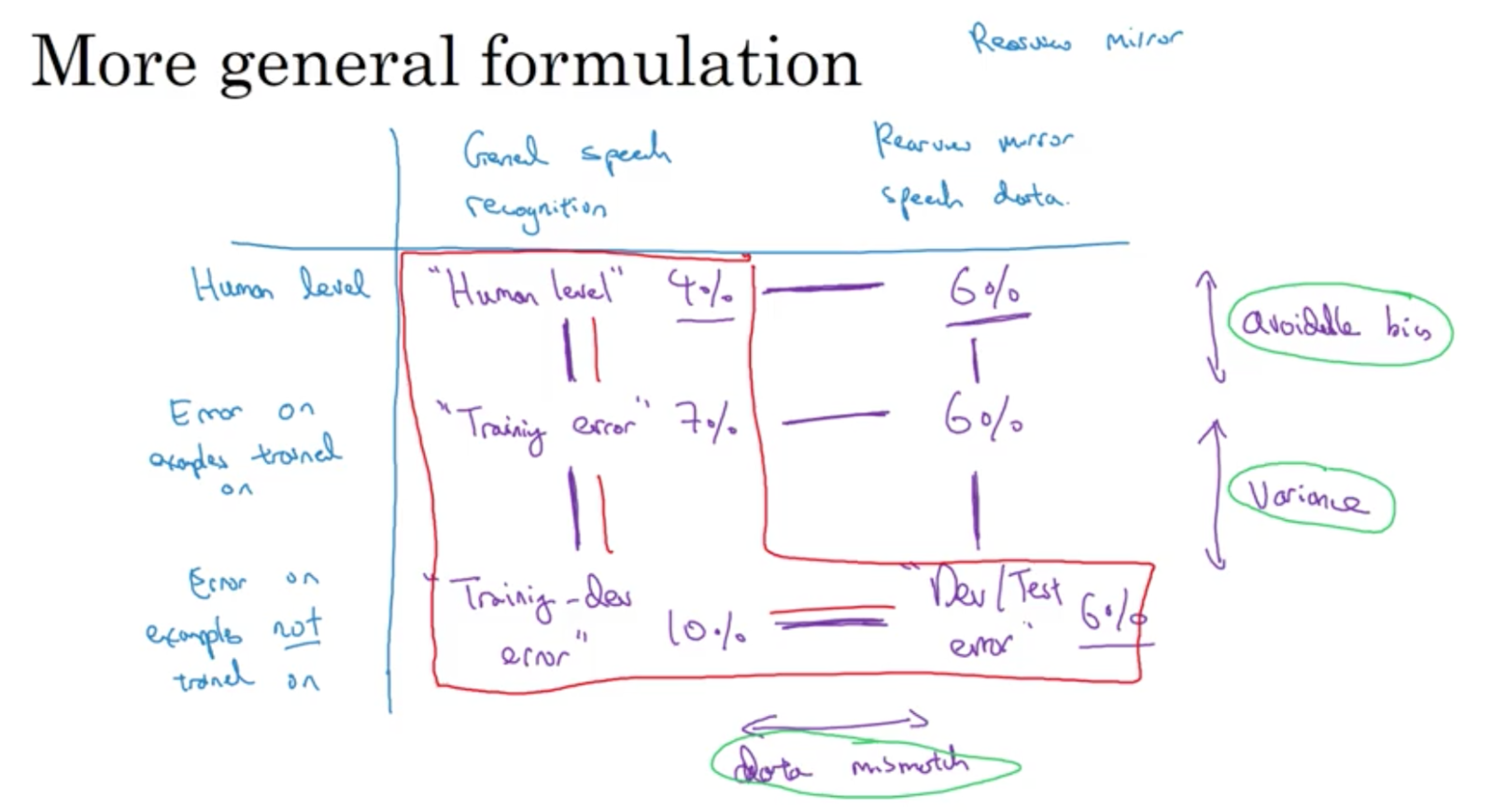
Bias and Variance with mismatched data distributions
Video #5 explores the counterpoint where you shouldn’t really use all the data you have. E.g. you can have dev and training data from different distributions, but a dev error of 10% and a training error of 1% - how do you know if your algorithm is fine?
Tease out these 2 effects (different distribution and variance problem) by making a new training-dev set, which has the same distribution as the training set, but is not used for training.
You could now have training 1%, training-dev 9% and dev 10% errors, and you can now conclude that you have a variance problem (1% - 9%) because training and training-dev are from the same distribution.
You could now have training 1%, training-dev 1.5% and dev 10% errors, and you can now conclude that you don’t have a variance problem, but a data mismatch problem.
The principles are:
Addressing data mismatch
There aren’t very super-systematic things for fixing data mismatch, but Video #6 discusses a few things you can try.
There might be some tell-tale things related to your application’s context which you can focus on to understand the difference between your training and dev/test sets. I.e. for voice navigation apps you can focus on ambient car noise and focus on getting street numbers right. So, collect similar training data, or simulate car noise in related data (e.g. combine audio of car noise with someone querying for a street address). This is called artificial data synthesis.
Be careful adding 1 hour of car noise to 10,000 hours of sound clips, because the model might overfit to the car noise. (My intuition: Try modifying the car clip: slow/fast, pitch up/down, generate similar white noise, etc.)
Be careful not to overfit to synthesised data.
Learning from multiple tasks
Transfer learning
Video #7 talks about re-purposing your neural networks.
You can take a network trained for image recognition, and delete the output node and the last set of weights, and randomly initialise those weights and re-train on X-ray data. Or re-train more layers. Or add more layers and and then a new output node.
This is called pre-training, and then using the X-ray data is fine-tuning. The image recognition network has learnt a lot about images and the structure of images (lines, dots, curves, etc), and this knowledge might come in useful in the X-ray images.
Another example is an audio transcript network and transferring to a wakeword/triggerword system.
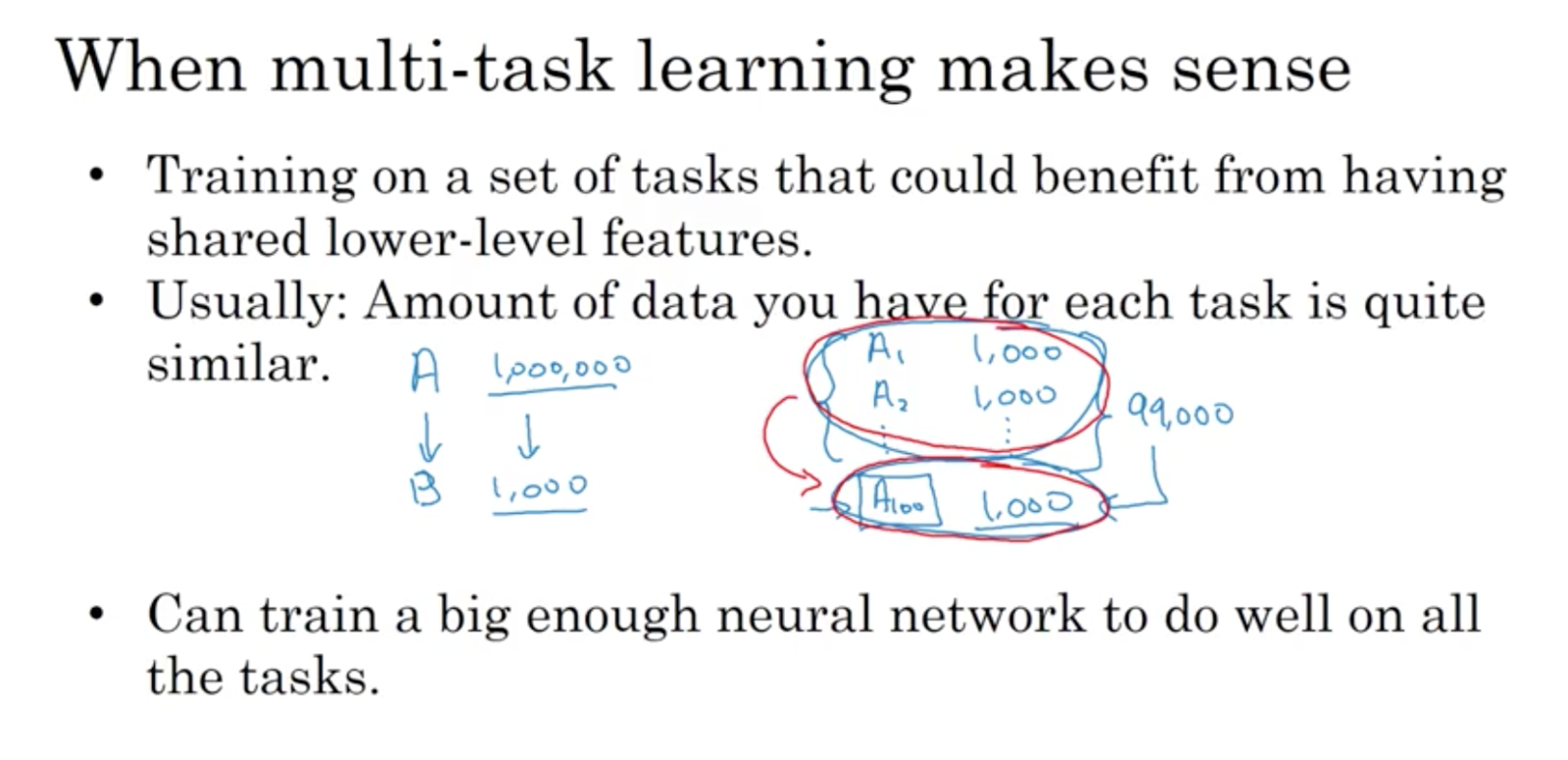
Transfer learning works well if you have a lot of data for the problem you are transferring from, but don’t have as much data for the problem you are transferring to.
It doesn’t work well if your root stock had an equal amount or fewer samples that your target samples.

Multi-task learning
Let’s say your autonomous car need to detect these 4 things:
- pedestrians
- cars
- stop signs
- traffic lights
(clearly this is a non-exhaustive list)
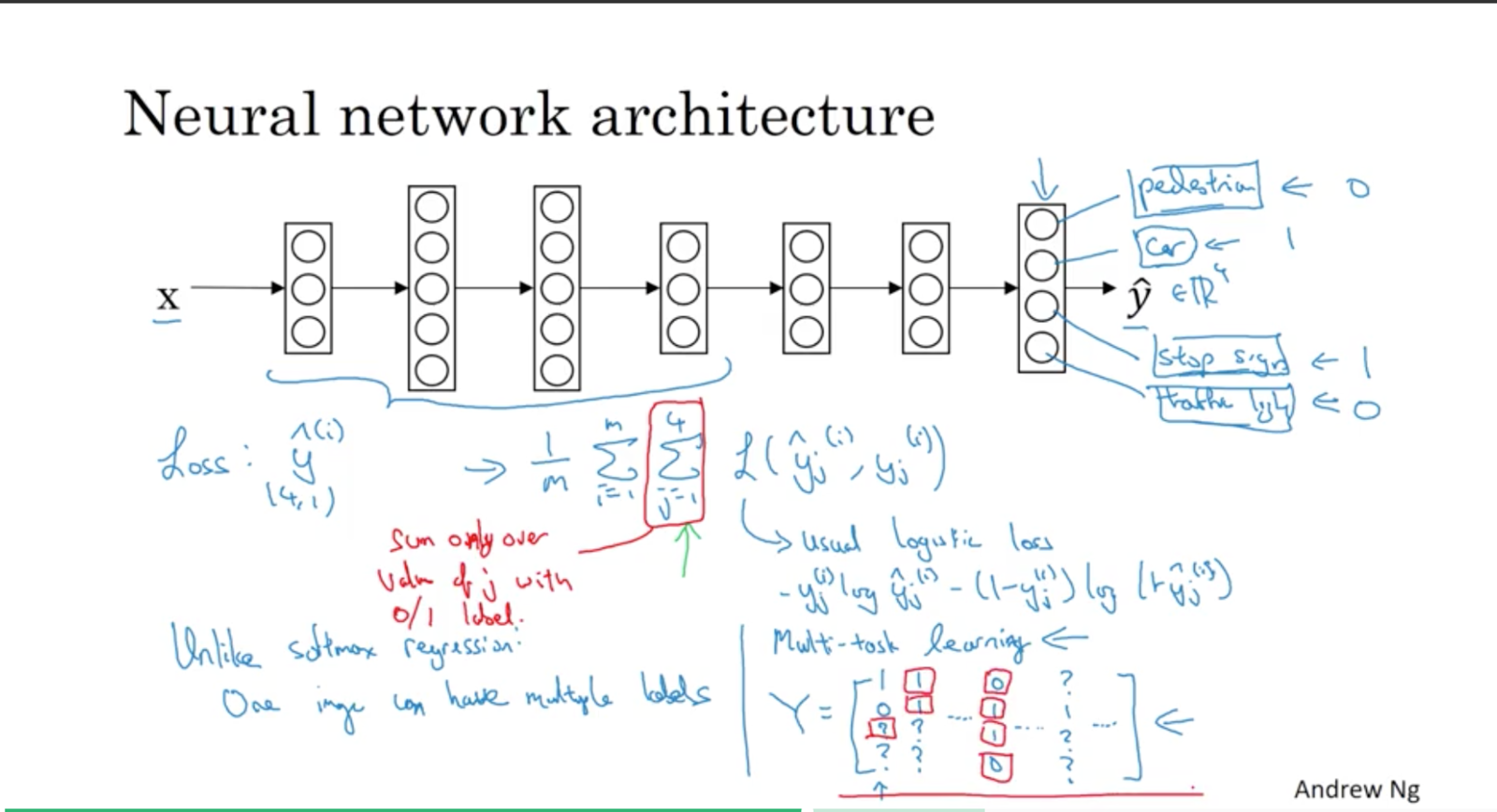
Where previously Y was a (1,m) matrix, it is now a (4,m) matrix.
Using this image as an input sample, you can see there’s 2 of the 4 features visible: stop sign and car.

You now train a NN to predict these values of Y. Yhat is now a 4 dimensional value for Y. Four output nodes.
Unlike softmax regression, this image can have multiple labels.
You could train 4 networks to predict these 4 things individually, but the base of the network can be shared because you’re detecting all objects, so the low-level features at the start of the network can be shared and this NN will give better performance.
For incomplete/unlabelled samples (e.g. you have training data where they didn’t bother to label whether there’s a car in the photo or not) you can just omit this term from the summation when calculating the loss.
End-to-end deep learning
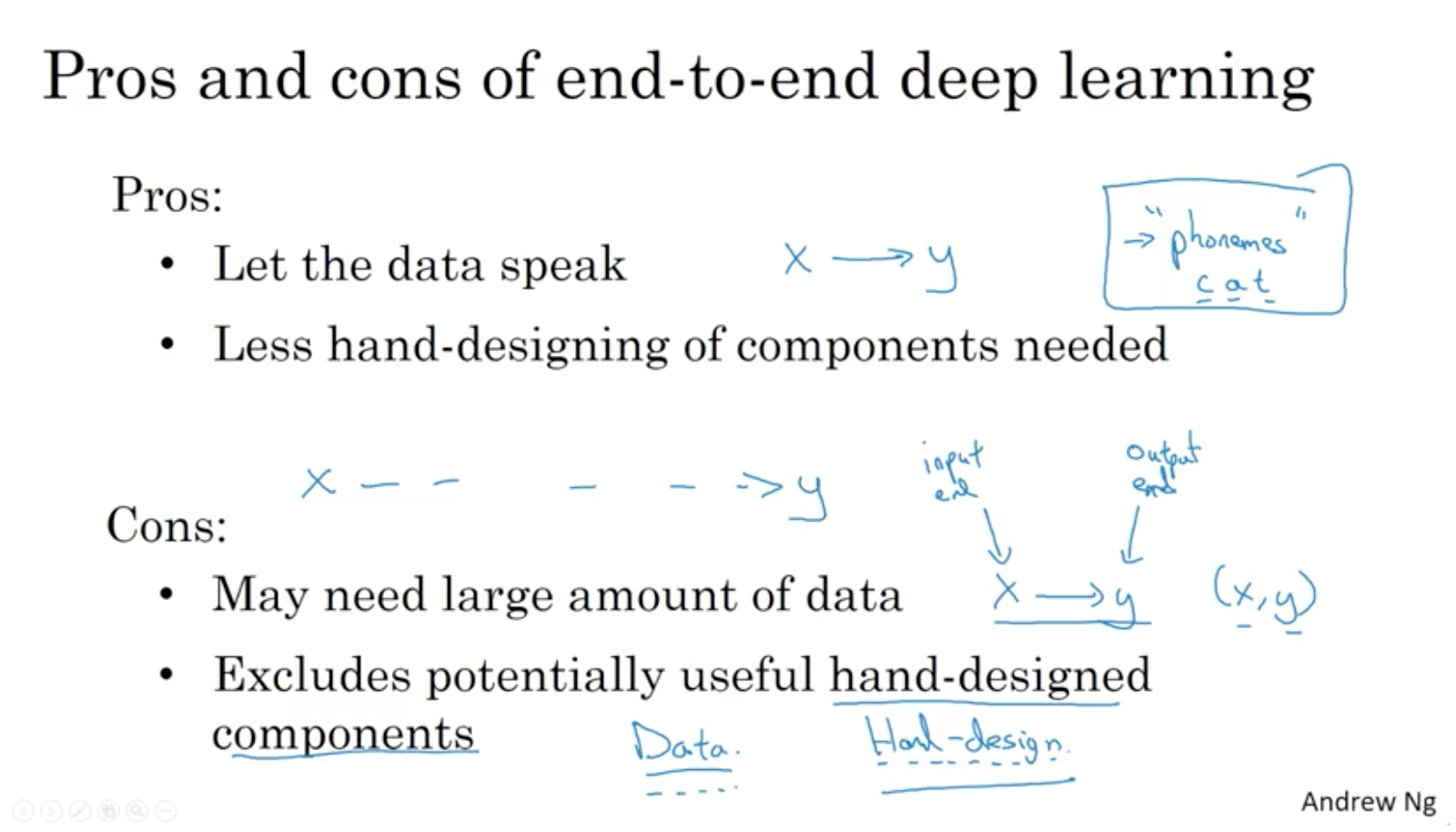
What is end-to-end deep learning?
Video #9 says that end-to-end is one of the most exciting recent developments in NN. Briefly: deep neural nets replacing previously multi-stage processing systems (sometimes obsoleting entire areas of research previously dedicated to subsystems).
E.g. audio -> MFCC for features -> ML for phonemes -> words -> transcript. A NN can just go from audio to transcript.
The old pipeline works well if you don’t have a lot of data, but deep learning trumps multi-stage if you have a lot of data.
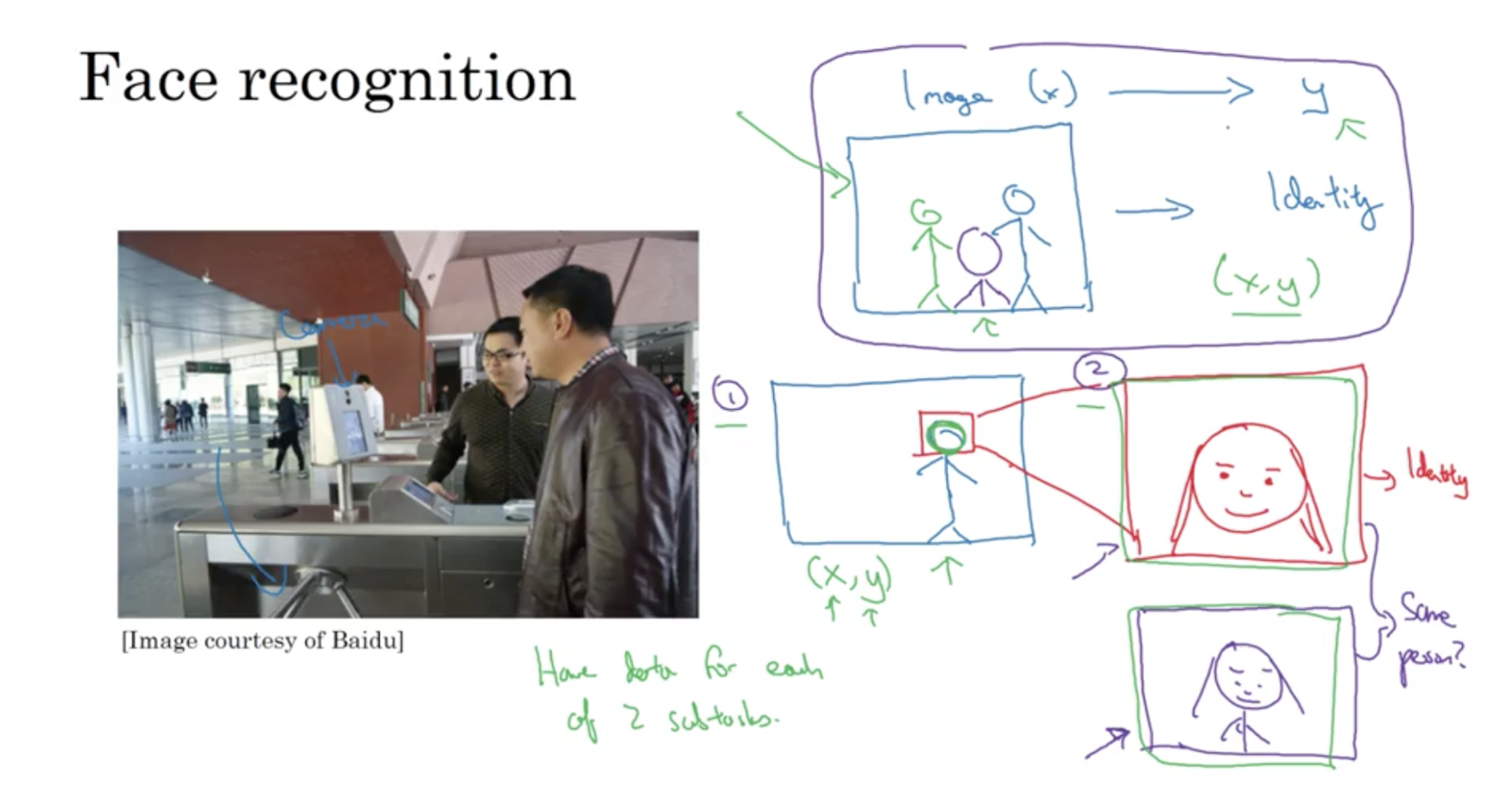
However, a multi-step approach might work better in some cases. E.g. face recognition. Instead of going from a photo (where the person can be near/far or anywhere in the photo) to identity, instead have stage 1 where you detect where the face is, and stage 2 which takes the zoomed-in face and compares this with all employee photos on file.
So, this is better because
- each individual problem is simpler and easier to solve
- you have a lot of data for each of the two subtasks:
- there are a lot of photos labelled with WHERE a face is in the photo
- there are a lot of photos of faces, and you can add your own labelled as “employee”
Whether to use end-to-end deep learning
Video #10 discusses what to weight up when deciding whether to use end-to-end or not.
Key question: do you have sufficient data to learn a function of the complexity needed to map x to y?
The Heroes of Deep Learning interviews feature Ruslan Salakhutdinov, director of AI research at Apple.
Ng poses the PhD VS industry question again, and I like Russ’ answer: academia would let you work on anything, any crazy idea, but industry allows you to see first-hand the effect of your work, and you’ll have more resources, like compute and multi-disciplinary teams to help in different ways. You can do amazing research in either setting.
And that wraps up the Structuring ML Projects course.
UPDATE achievement unlocked